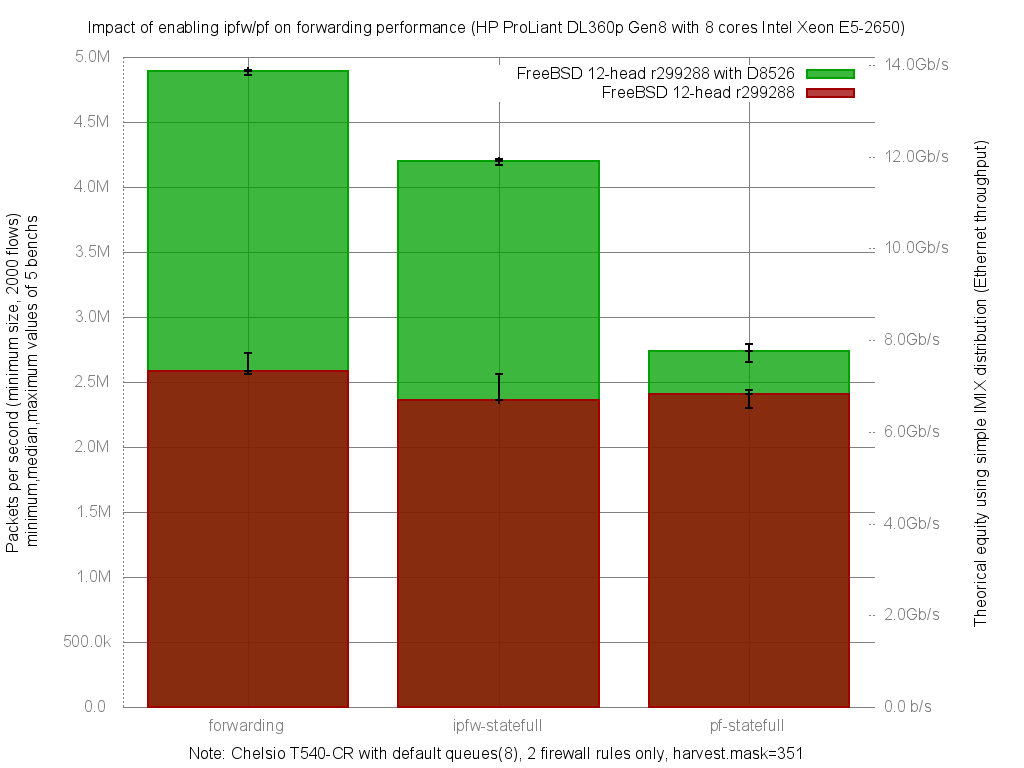
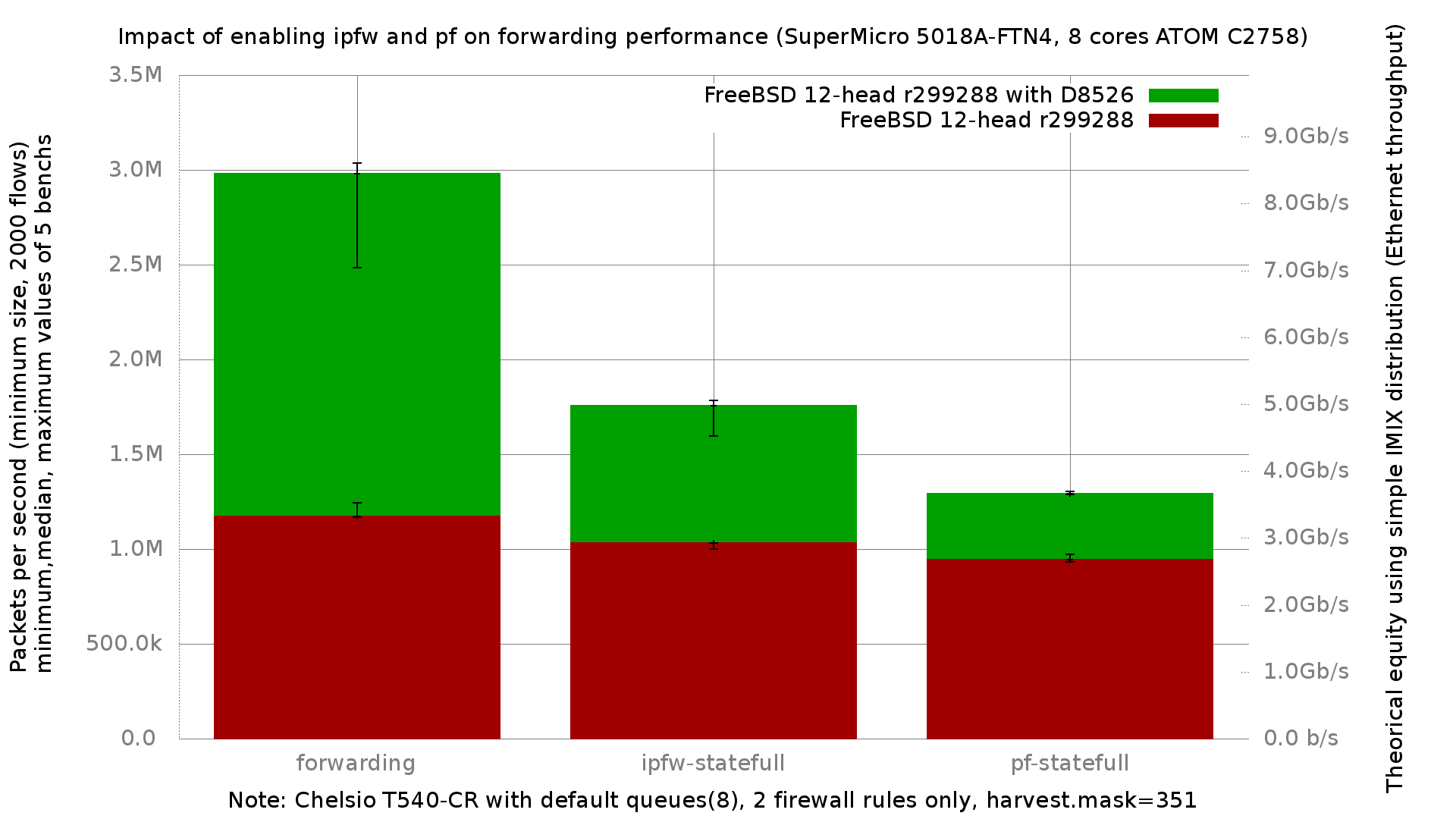
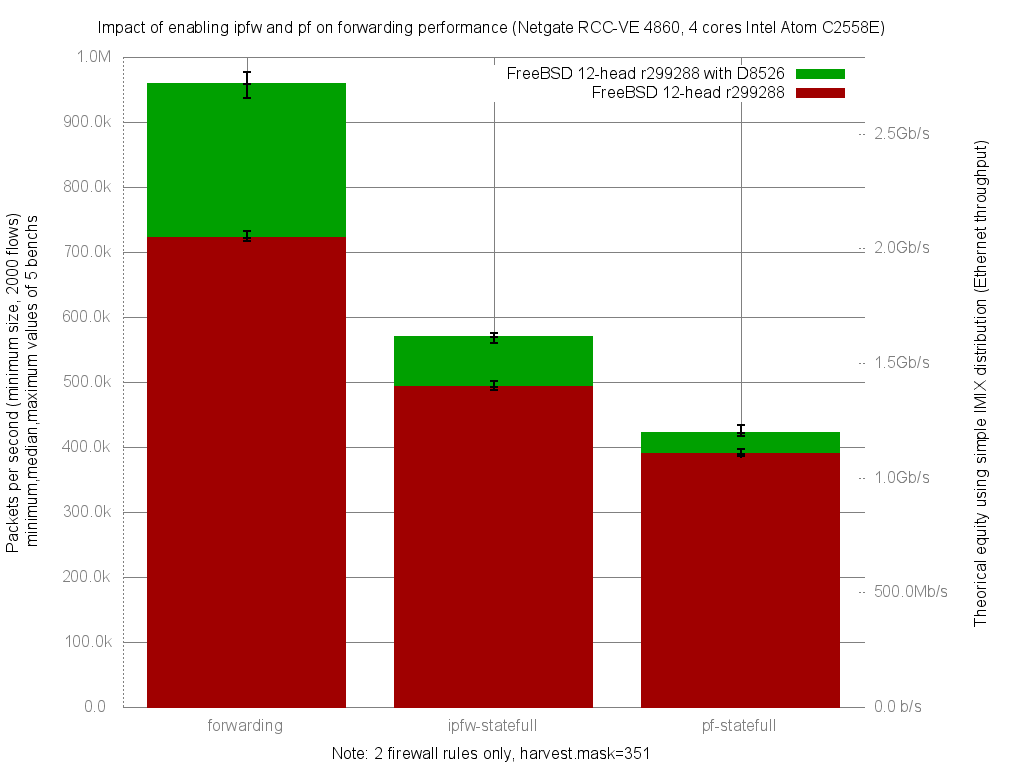
Вчера я закоммитил новый модуль для ipfw - ipfw_pmod, а так же смержил в stable/11 модули ipfw_nptv6 и ipfw_nat64.
Во FreeBSD 11.0 в ipfw было добавлено много нового, и среди прочего - поддержка "внешних действий", или external action. Она представляет собой интерфейс, который даёт возможность в рантайме добавлять и удалять в ipfw дополнительные действия для правил (actions, такие как allow, deny, count и прочие) .
Как это планировалось использовать в теории. Предположим, у нас имеется стоковая FreeBSD, и ряд задач для ipfw, которые строго специфичны для нашей организации, и всем другим людям такие функции вряд ли потребуются. Чтобы не добавлять подобные функции в базовую систему, и в то же время, чтобы упростить поддержку внутри организации (адаптацию патчей с каждой новой версией), были добавлены несколько новых опкодов.
Этих опкодов (сначала их было два, теперь стало три) достаточно, чтобы реализовать практически любую новую функцию в ipfw. Имеются в виду опкоды типа action. Достаточно только подгрузить модуль ядра и правила, использующие эти новые действия будут работать. Даже стоковый бинарник ipfw(8) способен с некоторыми ограничениями отображать такие правила. Для добавления и модификации таких правил необходимо стороннее приложение, исходный код которого менять при обновлении нет необходимости.
В случае если подобный модуль достаточно полезен и для всех других людей, то достаточно включить код для добавления и отображения правил в состав ipfw(8). Ядерная же составляющая остаётся без изменений.
Используя этот интерфейс были созданы три, перечисленные в начале, модуля. Модуль ipfw_pmod предназначен для модификации пакетов различных протоколов. На данный момент он содержит в себе только опкод "tcp-setmss", который как нетрудно догадаться, модифицирует опцию TCP пакета MSS. Правило использующее это действие может выглядеть, например, так:
ipfw add tcp-setmss 1400 tcp from any to any
Работает оно примерно так же, как netgraph модуль ng_tcpmss. Но ещё и поддерживает IPv6. После обработки правилом, действие продолжается со следующего правила. Т.е. правило не прерывает поиск.
Модуль ipfw_nptv6 реализует транслятор IPv6 префиксов и работает по алгоритму, описанному в RFC6296. Сразу хочу заметить, что трансляция IPv6 префиксов происходит несколько иначе, как можно было бы ожидать. Адреса не транслируются 1 в 1, например 2001:1000::1 не будет оттранслирован в 2a02:6b8::1. Согласно RFC адреса транслируются таким образом, что у транслятора нет необходимости делать пересчёт контрольных сумм. Поэтому в адрес добавляется некоторое число, которое делает вид адреса менее читаемым.
Использование этого модуля несколько отличается от ipfw_pmod. Здесь применяется концепция именованных экземпляров (instance) со своими собственными настройками. Прежде чем использовать nptv6 в правилах, необходимо создать именованный экземпляр и настроить его. После этого уже можно добавлять правила в ipfw:
Модуль ipfw_nat64 реализует транслятор IPv6 в IPv4. Он содержит две реализации stateful и stateless, и тоже использует концепцию именованных экземпляров. NAT64 без отслеживания состояний настраивается при помощи ключевого слова nat64stl. Он использует две таблицы, содержащие отображение IPv6->IPv4 и IPv4->IPv6. Согласен, это не очень удобно, но пока так.
NAT64 с отслеживанием состояний использует ключевое слово nat64lsn. Для его настройки нужен только используемый IPv4 префикс, который определяет количество ресурсов необходимых транслятору.
Оба транслятора используют Well-Known IPv6 префикс для NAT64 64:ff9b::/96. Ну и для работы конечно же нужен работающий DNS64.
Модуль ipfw_nptv6 реализует транслятор IPv6 префиксов и работает по алгоритму, описанному в RFC6296. Сразу хочу заметить, что трансляция IPv6 префиксов происходит несколько иначе, как можно было бы ожидать. Адреса не транслируются 1 в 1, например 2001:1000::1 не будет оттранслирован в 2a02:6b8::1. Согласно RFC адреса транслируются таким образом, что у транслятора нет необходимости делать пересчёт контрольных сумм. Поэтому в адрес добавляется некоторое число, которое делает вид адреса менее читаемым.
Использование этого модуля несколько отличается от ipfw_pmod. Здесь применяется концепция именованных экземпляров (instance) со своими собственными настройками. Прежде чем использовать nptv6 в правилах, необходимо создать именованный экземпляр и настроить его. После этого уже можно добавлять правила в ipfw:
ipfw nptv6 NPT create int_prefix fd00:dead:c0de:: ext_prefix 2001:470:7ad7:: prefixlen 48 ipfw add nptv6 NPT ip6 from any to any
Модуль ipfw_nat64 реализует транслятор IPv6 в IPv4. Он содержит две реализации stateful и stateless, и тоже использует концепцию именованных экземпляров. NAT64 без отслеживания состояний настраивается при помощи ключевого слова nat64stl. Он использует две таблицы, содержащие отображение IPv6->IPv4 и IPv4->IPv6. Согласен, это не очень удобно, но пока так.
NAT64 с отслеживанием состояний использует ключевое слово nat64lsn. Для его настройки нужен только используемый IPv4 префикс, который определяет количество ресурсов необходимых транслятору.
Оба транслятора используют Well-Known IPv6 префикс для NAT64 64:ff9b::/96. Ну и для работы конечно же нужен работающий DNS64.